pagespeed10x - Docker: Web-Performance-Daten aus PageSpeed Insights sammeln, in InfluxDB 2 speichern
Als Frontend-Entwickler war Web-Performance schon immer ein Teil meiner Arbeit, aber dieser Teil hatte keinen besonderen Fokus. Seit etwa einem Jahr hat sich das geändert. Dabei schaue ich mir häufig Performance-Daten von Googles PageSpeed Insights-Dienst an und vergleiche die Werte und betrachte die Entwicklung im Verlauf. Das manuelle Anstoßen des Dienstes und anschließende Notieren der Daten wurde dann aber doch etwas aufwändig. Was macht man da als Software-Entwickler? Automatisieren. Aus dem kleinen Script für mich wurde dann ein ganzes Projekt, das ich letzte Woche bei GitHub veröffentlich habe.
Die Anfänge
Wie so häufig bei so etwas hat sich die Sache entwickelt. Am Anfang stand ein simples Script, was ich ohne Parameter auf der Konsole aufgerufen habe und das einmal von oben nach unten durch lief und mir die Ergebnisse ausgegeben hat. Mit der Zeit wollte ich die Daten dann speichern, also ergänzte ich eine Speicherung in einer simplen SQLite-Datenbank.
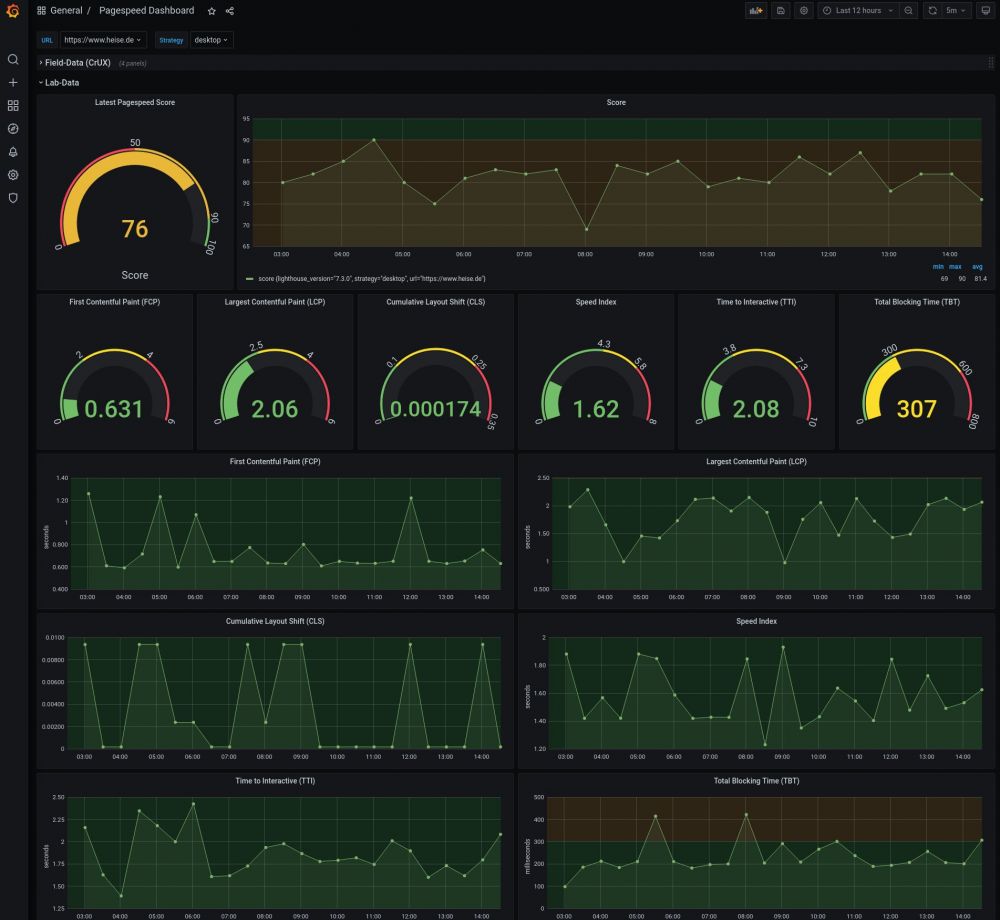
Visualisieren wollte ich die Daten aber auch irgendwie. Ein Trend lässt sich zwar auch aus Zahlen ablesen, aber leichter und schneller geht es einfach mit einer grafischen Darstellung. Anfang des Jahres hatte ich mich etwas mit Icinga2 und Grafana beschäftigt, weshalb ich über Grafana gestolpert war und diese Software zur Visualisierung auserkoren hatte. Jetzt brauchte ich noch etwas für „dazwischen“. Nach etwas Recherche entschied ich mich für InfluxDB als Time-Series-Datenbank. Meine Anforderungen schienen mir passend zu dieser Technik-Entscheidung. Ich würde viele Daten schreiben und im Prinzip nie Daten ändern wollen, denn ich arbeite ja mit Messergebnissen, die ich natürlich nicht nachträglich anpasse.
Alles zusammen bringen
Mein Technik-Setup hatte ich nun zusammen. Ein Python-Script, das die PageSpeed Insights-API abfragt und anschließend die Daten in eine InfluxDB schreibt. Am Ende der Kette dann eine Grafana-Instanz mit einem Dashboard, welches die Daten aus der InfluxDB ausliest und sinnvoll darstellt. Wie bringt man das ganze nun im Jahr 2021 ordentlich zusammen? Natürlich mit Docker. Ich hatte zwar schon mit Docker gearbeitet, aber eher um mal irgendwas auszuprobieren, wo mich dann auch nicht unbedingt interessiert hat, ob die Daten aus dem Docker-Container gespeichert wurden oder ob das Setup dann doch noch manuelle Arbeiten brauchte. Ich sag‘s mal so: Es lag viel Erkenntnisgewinn vor mir.
Lernen Lernen Lernen
Apropos Erkenntnisgewinn. Im Prinzip habe ich mit diesem Programm diverse Dinge neu gelernt. Einerseits viel im Umgang mit Docker, andererseits aber auch mit den einzelnen Software-Bestandteilen.
Das Python-Script
Mein Python-Script war als simples Ablauf-Script gestartet. Ich schrieb es um zu mehreren Modulen, die dann auch testbar wurden, sodass ich nun auch Unittests hinzufügen konnte. Des Weiteren setzte ich mich damit auseinander, wie ich dafür sorgen konnte, dass die nötigen Abhängigkeiten installiert wurden im Docker-Container. Da ich mich mittlerweile auch entschieden hatte das Projekt zu veröffentlichen musste ich den Code natürlich auch robuster machen. Wenn irgendwo was umkippt würde ich als Autor des Codes schnell wissen was der Fehler sein könnte oder auch wie ich dem Script Parameter zu übergeben habe, aber andere Nutzer*innen des Scripts würden das natürlich nicht wissen und eventuell Fehler machen. Ich schrieb also Dokumentation, prüfte Eingaben auf korrekte Typen und beschäftigte mich mit Exception-Handling in Python und überlegte mir wann ich fand, dass mein Script bei einem Fehler abbrechen sollte oder wann es einfach nur einen Fehler ausgeben, aber anschließend weiter machen sollte bzw. wann das sinnvoll wäre. Dann ergab sich natürlich noch die Schwierigkeit, dass sich das Script und die anderen Docker-Container Informationen teilen mussten. Wo ich anfangs einfach die InfluxDB mit bestimmten Daten von Hand eingerichtet hatte und diese Zugangsdaten dann im Script hinterlegt hatte erschien mir dieser Ansatz nicht einfach genug, um ihn Leuten aufzuerlegen, die meine kleine Software-Zusammenstellung einfach schnell nutzen wollen. Ich entschied mich dazu, dass alles, was konfigurierbar ist bzw. sein musste über Umgebungsvariablen konfiguriert wird. So konnten die Daten an einer Stelle liegen, aber das Script kann die Daten genauso lesen wie das Dockerfile zum Setup des InfluxDB-Containers.
InfluxDB 2
Als ich mich für InfluxDB entschied habe ich bewusst InfluxDB 2 gewählt. Die vorige 1.x-Version wird zwar immer noch unterstützt, aber wieso sollte ich auf eine alte Software setzen? Die Doku sah auch gut aus, es sprach also nichts dagegen. Und dann kam die Realität. InfluxDB ist kein Neuling, gerade im Zusammenhang mit Grafana wird es gerne und häufig eingesetzt. Auch IoT (Internet of Things) Projekte benutzen es gerne zum loggen von Messdaten. Aber der Großteil der Projekte benutzt die alte Version, die noch ein ganz anderes Setup hat. Viele Suchergebnisse zu meinen Problemen passten also nicht zur Version 2. Aber hey, es gab ja gute Doku – kein Ding also. Oder? Nunja, auf meinem Zettel steht jedenfalls noch eine Mail zu schreiben, dass die Doku eher so mäßig gut ist und wo da was verbessert werden könnte. Es gibt einen extra Abschnitt zu Docker, aber zur anschließenden Einrichtung wird dann nur erklärt, dass man sich in den Container einwählen und dort die Setup-Prozedur durchlaufen kann. Kein Wort an dieser Stelle, dass es eine Möglichkeit für ein automatisches Setup gibt. Durch Zufall bei der Recherche zu einem anderen Problem stieß ich darauf, dass es mehrere Umgebungsvariablen gibt mit denen man alle wichtigen Informationen für das Setup reinreichen kann und der Container so anschließend direkt eingerichtet ist ohne dass man sich noch selbst einwählen muss. Das nächste war dann der Abschnitt zum Persistieren der Daten, die der Container erzeugt – also meine Messdaten. Gerade beim Betrachten der Performance möchte man ja auch mal auf längere Zeiträume blicken um zu beurteilen, wie sich die Performance einer URL entwickelt hat. In der Doku wird auch ein Pfad zum Mounten eines Volumes genannt für die Persistenz – nur leider wird da standardmäßig nichts gespeichert. Anfangs dachte ich, dass ich Rechte-Probleme hätte mit meinem Volume auf dem Host-System (eingeschränkter User) und dem InfluxDB-Docker-Container, welcher intern als root läuft. Aber das war es nicht. Bei weiteren Recherchen – ich war nicht der einzige mit diesem Problem – stieß ich dann endlich auf die richtigen Pfade um die erzeugten Container-Daten außerhalb zu sichern. Das waren die größten beiden Hürden beim InfluxDB-Setup. Beim Grafana-Dashboard brauchte ich dann noch etwas um mich mit der Abfrage-Sprache von InfluxDB anzufreunden, Flux genannt, aber als ich die ersten Daten dann mal erfolgreich abgefragt hatte erschloss sich mir das Prinzip.
InfluxDB und RaspberryPi verdienen hier eine extra Erwähnung. Meine Idee war nämlich zu Anfang das Ganze Setup auf einem RasPi lauffähig zu haben. Genauergesagt auf meinem RasPi 3 (32-Bit armv7 Architektur). Das sollte zwar nicht das Standard-Setup sein, aber ich hätte dann in der Doku erwähnt, wie man das Ganze anpassen müsste oder eine zweite Konfiguration hinterlegt. Eigentlich gibt es das InfluxDB 2-Docker-Image aber nicht für diese Architektur. Jedoch fand ich nach etwas Recherche auf Docker-Hub eine arm32v7-Variante und dort stand explizit „The latest tag for this image now points to the latest released implementation of InfluxDB 2.x“. Super, dachte ich – genau was ich brauchte. Ich passte also meine docker-compose.yml an, sodass sie dieses Image ziehen würde. Das funktionierte auch, aber irgendwas passte nicht. Anfangs suchte ich nach Fehlern in meinem Setup und meinem Script. Während der Analyse wollte ich einmal wissen, welche 2.x-Version genau denn gerade durch latest verwendet wird und war verdutzt: da stand eine 1.x-Version. Ich checkte meine docker-compose-Datei, ob ich nicht gespeichert hatte oder irgendwas anderes falsch gemacht hatte, weshalb evtl. noch auf die 1.x-Version verwiesen wurde, aber dort schien alles korrekt. Auf der Detail-Seite des latest-Tag des Image bei Docker-Hub fand ich dann die Lösung. In der Auflistung der Image-Layer fand sich die Zeile „ENV INFLUXDB_VERSION=1.8.4“ – tja, okay. Wohl doch keine Version 2 für arm32v7, wie es der Text versprach. Schade.
Grafana
Wo ich gerade von Grafana sprach. Das Docker-Setup war relativ einfach. Die Dokumentation ist auch ordentlich und war hilfreich. Hier waren meine Hürden vor allem, wie ich Grafana so vorkonfiguriert bekomme, dass Nutzer*innen meines Scripts keine weitere Einrichtung mehr vornehmen müssen. Vor allem ging es dabei um InfluxDB als Datenquelle mit den richtigen Zugangsdaten aus dem Setup und dass mein Dashboard eingerichtet sein sollte. Da dies aber keine ungewöhnlichen Anforderungen waren ließen sich dazu glücklicherweise leicht Informationen im Internet finden und meine Arbeit bestand dann hauptsächlich aus der Konfiguration des Dashboards. Hierzu habe ich es vor allem einige Zeit selbst benutzt um ein Gefühl dafür zu bekommen, welche Informationen mir wichtig waren und wie ich sie dargestellt haben wollte. Das schöne an den Dashboards bei Grafana ist aber, dass sie editierbar sind. Jemand kann also einfach das Dashboard für sich völlig umbauen nach eigenen Anforderungen. Einzig sollte man bei Anpassungen das Dashboard unter neuem Namen speichern, damit es nicht später wieder mit dem vorkonfigurierten überschrieben wird.
Docker
Vorhin hatte ich ja schon erwähnt, dass mir Docker nicht prinzipiell neu war, aber alles in einem docker-compose-Setup zusammen zu bringen und noch ein Dockerfile für mein Script zusätzlich zu haben erforderte dann doch noch einiges an Recherche. Dies war auch zum Teil dem Umstand geschuldet, dass hier gleich mehrere Dinge zusammen kamen, die für mich neu waren. So dachte ich beispielsweise bei den Volumes von InfluxDB anfangs, dass ich einen Fehler im Docker-Setup hatte, weshalb keine Dateien gespeichert wurden. Schließlich gab die InfluxDB-Doku ja konkret an, was man wohin mounten sollte. Die Erkenntnis, dass die Doku fehlerhaft war und mein Volume die ganze Zeit über korrekt gewesen ist brauchte dann halt etwas Zeit. Eine andere Erkenntnis, die erst einige Recherche benötigte, war im Zusammenhang mit Build-Arguments. Zwischendurch wollte ich ein Problem mit Build-Arguments lösen, letztlich ist diese Lösung aber gar nicht im Code geblieben. Jedenfalls kostete es mich etwas Zeit herauszufinden, dass ich ein Build-Argument im Dockerfile nach der Angabe eines Image nennen muss, damit ich es verwenden kann. Ich hatte das Build-Argument halt am Anfang des Dockerfile definiert und dachte länger, dass mein Problem irgendwo anders in der Kette von der docker-compose.yml zum Dockerfile zum Python-Script lag. Dass ich die Zeile einfach nur mit der darunterliegenden tauschen musste war dann zum Schluss doch glücklicherweise eine einfache Lösung.
Aus diesem Script eine halbwegs vorzeigbare Software zu machen hat doch nochmal ein gutes Stück Arbeit gekostet, aber es hat sich auf jeden Fall gelohnt. Einerseits können sie nun auch andere Menschen nutzen und andererseits haben mir einige dieser Verbesserungen auch bereits selbst geholfen (z.B. das bessere Exception-Handling). Darüber hinaus habe ich selbst natürlich auch mal wieder viel neues gelernt, was eigentlich eh immer gut ist!